面试笔记
List
ArrayList的扩容机制
扩容是懒惰式的,即:没有添加元素之前,即使指定了容量,也不会真正的创建数组。
add(Object o)方法首次扩容为10,再次扩容:创建一个为原来容量1.5倍(=原来容量+原来容量>>1)的,将原来的复制过来,再添加一个元素进去。addAll(Collection c)首次扩容为Math.max(10, 实际元素个数)。再次扩容(有元素时)为Math.max(原来1.5倍, 实际元素个数)。
Fail-Fast 和 Fail-Safe
Fail-Fast
ArrayList是Fail-Fast的典例,遍历时不可修改。
在增强for循环的地方进行断点调试,进入断点会发现创建了一个迭代器,迭代器在初始化的时候,会进行相关成员变量的初始化。在迭代器判断是否有下一个元素的时候,next()方法校验如果发现list的修改次数(modCount)发生了改变,则直接抛出
ConcurrentModificationException异常。Fail-Safe
CopyOnWriteArrayList是Fail-Safe的典例,遍历时可修改,原理是读写分离。
在遍历的时候,我们会发现,它使用的是一个叫
COWIterator迭代器,它实际遍历的是原始数据集合的一个快照。通过在调用add()方法添加元素的时候,我们也可以看到,它本身也是对数组进行了一个复制。
ArrayList 与 LinkedList 的比较
- ArrayList
- 基于数组,需要连续存储。
- 随机访问快(根据下标访问)。
- 尾部插入、删除性能可以,其他部分插入、删除都会移动数据,因此性能会低。
- 可以利用cpu缓存,局部性原理(系统认为:某一元素相邻的一些数据也是有很大概率会被访问,所以读取某一元素时会将相邻的一些数据同时缓存,提高处理效率。但是链表结构的就不行,因为指针指向的下一元素大可能并不在相邻位置)。
- LinkedList
- 基于双向链表,无需连续存储。
- 随机访问慢(要沿着链表遍历)。
- 头尾插入删除性能高。
- 占用内存多。
HashMap
底层数据结构1.7和1.8的不同?
- 1.7:数组 + 链表。
- 1.8:数组 + 链表或者红黑树。红黑树可以避免链表过长的情况。
使用红黑树的意义?
为何要使用红黑树?
红黑树:自平衡二叉树,每一个节点上,小的在左边节点,大的在右边节点。
为什么不一上来就树化?
- 链表短的情况下,树化并不会提高性能。
- 链表的成员变量是node,树的成员变量是treeNode,占用的内存会更多一点。
树化的阈值为何是8?
正常情况下,链表的长度不会超过8。
红黑树用来避免DoS攻击,防止链表超长时性能下降,树化应当是偶然现象,选择8就是为了让树化的几率足够小。
链表何时会树化?
需要同时满足2个条件:
- 链表长度超过阈值8。
- 整个数组的长度要大于等于64,没到64会优先进行扩容。
何时会退化为链表?
情况1:扩容时,如果拆分树后,树元素个数 <=6 则会退化链表。
情况2:remove树节点前检查:若root、root.left、root.right、root.left.left有一个为null,则会退化为链表。
索引(桶下标)的计算
计算对象的hashCode,再调用
HashMap的hash()方法进行二次哈希,最后求模运算(%capacity)得到索引。二次哈希是为了综合高位的数据,让哈希分布更为均匀。
为什么数组容量为2的n次幂?因为2的n次幂可以使用位与运算代替取模,效率更高;
扩容的时候,如果 hash & oldCapacity == 0 的元素留在原来的位置,
否则,新位置 = 旧位置 + oldCapacity。
扩容负载因子:0.75,即:当元素达到容量的3/4时,进行扩容。
HashMap put流程
HashMap是懒惰式创建数组,首次使用的时候才创建数组。
计算索引(桶下标):
如果桶下标还没被占用:
创建Node占位返回。(多线程这边可能会引发丢失问题)
如果桶下标已经被占用:
如果已经是TreeNode走红黑树的添加或者更新逻辑;
如果是普通的Node,走链表的添加或修改逻辑,如果是长度超过树化阈值的,走树化逻辑。
返回前检查容量是否超过阈值,一旦超过进行扩容。
put 方式在 Java 1.7和1.8中的不同:
链表插入节点时,1.7是头插法,1.8是尾插法。
注:头插法在扩容后,链表顺序会发生改变,因为重新插入,所以顺序会反过来。多线程当中,头插法在扩容后可能会存在死链问题(即:a -> b -> a)
1.7是大于等于阈值且没有空位的时候才扩容,1.8是大于阈值就扩容。
1.8在扩容计算Node索引的时候,会优化。
负载因子为什么默认是0.75f
在空间占用与查询时间之间取得较好的平衡:
大于这个值,空间节省了,但链表就会变长影响性能。
小于这个值,冲突减少了,但扩容就会更频繁,空间占用更多。
HashMap在多线程下的问题
- 扩容死链(1.7,参考put流程扩容后的头插法)
- 数据混乱(1.7和1.8,参考put流程索引计算)
HashMap的key能否位null,作为key的对象有什么要求
- HashMap 的key可以位null。
- 作为key的对象,必须重写 hashCode()和equals()方法,并且key的内容不可变(比如我们常用的String就是不可变的,作为key,如果是自定义对象,对象发生了改变,就没法通过key的hashCode找到value)。
String 的 hashCode如何设计的,为什么是每次乘以31
目的是为了达到较为均匀的散列效果,每个字符串的hashCode足够独特。
根据其散列公式得知:31带入公式有较好的散列特性,并且 31 * h 可以被优化为:
32 * h - h 等价于: 2^5 * h - h 等价于: h << 5 - h
设计模式
单例模式
常见单例模式
饿汉式 - 静态代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36package pattern;
import java.io.Serializable;
/**
* 单例模式 - 饿汉式
*/
public class Singleton1 implements Serializable {
private Singleton1(){
// 判断,避免通过反射的方式再创建对象
if(INSTANCE != null){
throw new RuntimeException("单例对象不能被重复创建!");
}
System.out.println("private Singleton1()");
}
private static final Singleton1 INSTANCE = new Singleton1();
public static Singleton1 getInstance(){
return INSTANCE;
}
public static void otherMethod(){
System.out.println("otherMethod()...");
}
/**
* 特殊方法,可以避免反序列化破坏单例
* @return
*/
public Object readResolve(){
return INSTANCE;
}
}饿汉式 - 枚举。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33package pattern;
/**
* 单例模式 - 饿汉式
* 枚举类方式
* 优点:
* 1. 可以避免反序列化破坏单例。
* 2. 可以避免反射破坏单例。(枚举不能通过反射创建实例)
*/
public enum Singleton2 {
/**
* 枚举变量(本身就是公共的,不提供公共方法也能使用)
*/
INSTANCE;
/**
* 构造函数(可省略)
*/
Singleton2(){
System.out.println("private Singleton2()");
}
/**
* 重写,方便查看实例的信息
* @return
*/
@Override
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}
}懒汉式 - DCL
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35package pattern;
import java.io.Serializable;
/**
* 单例模式 - 懒汉式 - DCL
*/
public class Singleton3 implements Serializable {
private Singleton3(){
System.out.println("private Singleton3()");
}
/**
* volatile 保证可见性,有序性,避免指令重排。
*/
private static volatile Singleton3 INSTANCE = null;
public static Singleton3 getInstance(){
if(INSTANCE == null){
synchronized (Singleton3.class){
if(INSTANCE == null){
INSTANCE = new Singleton3();
}
}
}
return INSTANCE;
}
public static void otherMethod(){
System.out.println("otherMethod()...");
}
}懒汉式 - 静态内部类方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30package pattern;
import java.io.Serializable;
/**
* 单例模式 - 懒汉式 - 静态内部类方式
* 原理:静态代码块具有线程安全的特性。
*/
public class Singleton4 implements Serializable {
private Singleton4(){
System.out.println("private Singleton4()");
}
/**
* 静态内部类方式的懒汉单例
*/
private static class Holder {
static Singleton4 INSTANCE = new Singleton4();
}
public static Singleton4 getInstance(){
return Holder.INSTANCE;
}
public static void otherMethod(){
System.out.println("otherMethod()...");
}
}
破坏单例的方式
反射破坏单例
可避免:构造函数中添加实例是否为空的判断,因为反射是通过构造函数来创建的。
1
2
3
4
5
6
7
8
9
10
11/**
* 破坏单例 - 通过反射创建实例
* 避免方式:可以通过构造函数添加判断来避免。
* @param clazz
* @throws Exception
*/
private static void reflection(Class<?> clazz) throws Exception{
Constructor<?> constructor = clazz.getDeclaredConstructor();
constructor.setAccessible(true);
System.out.println("反射创建的实例:" + constructor.newInstance());
}反序列化破坏单例
可避免:单例类中添加
readResolve()方法,方法中返回实例对象。1
2
3
4
5
6
7
8
9
10
11
12
13/**
* 破坏单例 - 通过反序列化创建实例
* 避免方式:可以通过添加特殊方法 readResolve() 来避免。
* @param instance
* @throws Exception
*/
private static void serializable(Object instance) throws Exception{
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(instance);
ObjectInputStream ois = new ObjectInputStream(new ByteArrayInputStream(bos.toByteArray()));
System.out.println("反序列化创建的实例:" + ois.readObject());
}Unsafe破坏单例
无法避免。
1
2
3
4
5
6
7
8
9
10/**
* 破坏单例 - 通过 Unsafe 创建实例
* 避免方式:无法避免。
* @param clazz
* @throws InstantiationException
*/
private static void unsafe(Class<?> clazz) throws InstantiationException {
Object o = UnsafeUtils.getUnsafe().allocateInstance(clazz);
System.out.println("Unsafe创建的实例:" + o);
}
JDK中哪些地方使用了单例模式
- Runtime(System.exit()和System.gc()方法的底层),饿汉式的单例。
- System中的Console对象,是一个双检锁形式的单例。
- Collections中静态内部类,如 EmptyXXX。
- Comparator中的Comparators.NaturalOrderComparator.INSTANCE,是一个枚举形式的单例。
多线程
线程有哪些状态
- new,新建
- runnable,可运行
- blocked,阻塞
- waiting,等待
- timed_waiting,有时限等待
- terminated,终止
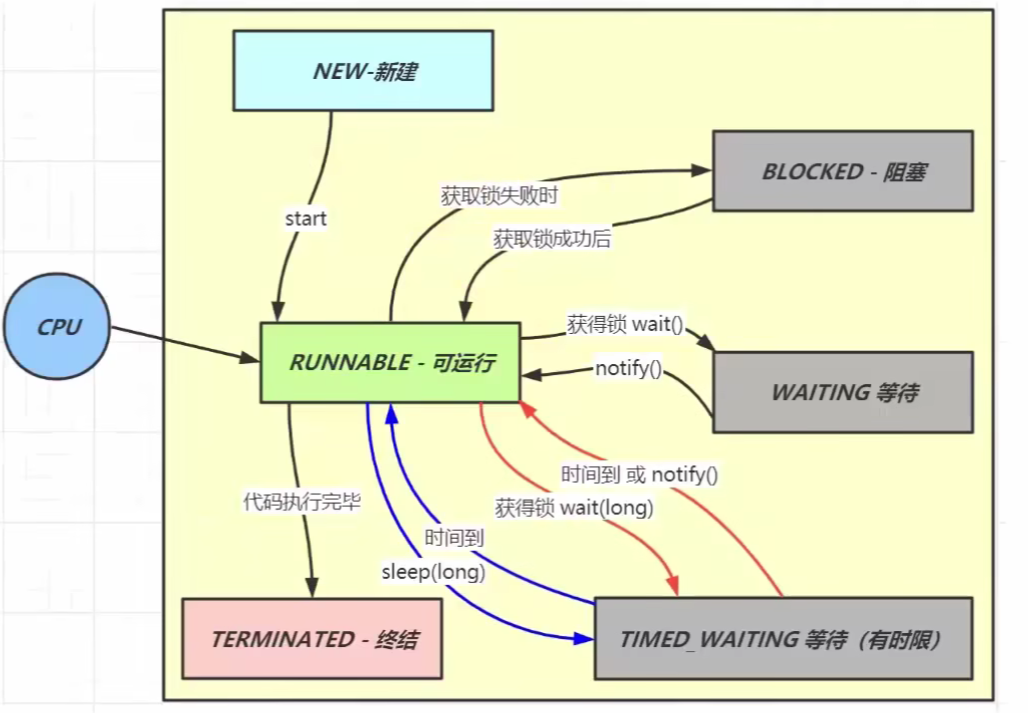
sleep() 和 wait() 的比较
- 方法归属不同
- sleep()是Thread的静态方法。
- wait()是Object的成员方法,每个对象都有。
- 唤醒时机不一样
- sleep()和wait()都会在等待相应时间后醒来。
- wait()还可以被notify()唤醒。
- 都可以被打断唤醒。
- 锁特性不一样
- wait()方法的调用必须先获取wait()对象的锁,而sleep()则不用。
- wait()方法执行后会释放对象锁,允许其他线程获得该对象锁。
- sleep()方法如果在synchronized代码块中,并不会释放锁。
实现线程的方式
继承Thread类,重写run()方法。
1)可以将线程类抽象出来,当需要使⽤抽象⼯⼚模式设计时。
2)多线程同步。
实现Runnable接口,重写run()方法,将实现类的实例作为Thread构造函数的target。
1)适合多个相同的程序代码的线程去处理同⼀个资源。
2)可以避免java中的单继承的限制。
3)增加程序的健壮性,代码可以被多个线程共享,代码和数据独⽴。
通过线程池创建。
实现Callable接口,通过FutureTask包装器来创建Thread线程。如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22package thread;
import java.util.concurrent.Callable;
import java.util.concurrent.FutureTask;
public class ThreadDemo {
public static void main(String[] args) {
Callable<Object> oneCallable = new Tickets<Object>();
FutureTask<Object> oneTask = new FutureTask<Object>(oneCallable);
Thread t = new Thread(oneTask);
System.out.println(Thread.currentThread().getName());
t.start();
}
}
class Tickets<Object> implements Callable<Object> {
@Override
public Object call() throws Exception {
System.out.println(Thread.currentThread().getName() + "-->我是通过实现Callable接⼝通过FutureTask包装器来实现的线程");
return null;
}
}
锁的等级:⽅法锁、对象锁、类锁
- ⽅法锁(synchronized修饰⽅法时)
- 对象锁(synchronized修饰⽅法或代码块)
- 类锁(synchronized 修饰静态的⽅法或代码块)
对象锁是⽤来控制实例⽅法之间的同步,类锁是⽤来控制静态⽅法(或静态变量互斥体)之间的同步。
如何保证多线程下 i++ 结果正确?
- volatile只能保证你数据的可⻅性,获取到的是最新的数据,不能保证原⼦性;
- ⽤AtomicInteger保证原⼦性。
- synchronized既能保证共享变量可⻅性,也可以保证锁内操作的原⼦性。
如果同步块内的线程抛出异常会发⽣什么?
synchronized⽅法正常返回或者抛异常⽽终⽌,JVM会⾃动释放对象锁。
Lock和synchronized两种锁的比较
语法层面
- synchronized 是关键字,源码在jvm中,用c++实现。
- Lock是接口,源码由jdk提供,用java实现。
- 使用synchronized时,退出同步代码块锁会自动释放,而使用Lock时,需要手动调用unlock()方法释放。
功能层面
二者都是悲观锁,都具备基本的互斥、同步、锁重入功能。
Lock提供了许多synchronized不具备的功能,例如获取等待状态、公平锁(先到先得)、可打断、可超时、多条件变量。
注:无参的tryLock()方法是非公平锁,有参的tryLock()是根据配置判断是否公平锁。
Lock有适合不同场景的实现,如ReentrantLock。
性能层面
- 在没有竞争的时,synchronized做了优化,如偏向锁、轻量级锁,性能不错。
- 在竞争激烈时,Lock的实现通常会提供更好的性能。
volatile 能否保证线程安全
线程安全主要考虑三个方面:可见性、有序性、原子性。
- 可见性,一个线程对共享变量修改,另一个线程能看到最新的结果。
- 有序性,一个线程内代码按照编写的顺序执行。
- 原子性,一个线程内多行代码以一个整体运行,期间不能有其他线程的代码插队。
volatile 能够保证共享变量的可见性和有序性,但不能保证原子性,所以还是会有线程安全的问题。
volatile 读写屏障
写屏障:在写指令之后插入写屏障,强制把写缓冲区的数据刷回到主内存中。
读屏障:在读指令之前插入读屏障,让工作内存或CPU高速缓存当中的缓存数据失效,重新回到主内存中获取最新数据。
悲观锁与乐观锁
悲观锁的代表是synchronized和Lock锁
- 核心思想:线程只有占有了锁,才能去操作共享变量,每次只有一个线程占锁成功,获取锁失败的线程,都必须停下来等待。
- 线程从运行到阻塞,再从阻塞到唤醒,这种状态的切换涉及线程上下文切换(每次操作都要记录与恢复上一次的执行位置),如果频繁发生,影响性能。所以实际上,线程在获取synchronized和Lock锁时,如果锁已经被占用,都会做几次重试操作,减少阻塞的机会。
乐观锁的代表是AtomicInteger,使用CAS(Compare And Swap)来保证原子性。
核心思想:无需加锁,每次只有一个线程能成功修改变量,其他失败的线程不需要停止,不断重试直至成功。
由于线程一直运行,不需要阻塞,因此不涉及线程上下文切换。
它需要多核CPU支持,且线程数不应超过CPU核数。
附:这里提到的cas指的是Unsafe.compareAndSetXXX(),该方法可以保证操作的原子性,方法返回一个boolean(true/修改成功,false/修改失败)。
CAS与ABA问题
Hashtable和ConcurrentHashMap的比较
Hashtable与ConcurrentHashMap都是线程安全的Map集合。
Hashtable并发度低,整个Hashtable对应一把锁,同一时刻,只能有一个线程操作它。
ConcurrentHashMap:
在1.8之前,使用Segment数组+HashEntry小数组+链表的结构,每个Segment对应一把锁,如果多个线程访问不同的Segment,则不会冲突。
注:Segment数(clevel)确认后不会扩容,能扩容的是HashEntry小数组。Segment[0]作为原型,Segment[0]的小数组容量的初始值=capacity/clevel,在Segment[n]上新建小数组的初始容量等于Segment[0]的,如果Segment[0]的小数组容量发生了扩容,那么之后的Segment[x]在新建时的小数组容量也是等于新的Segment[0]的小数组容量。
在1.8之后,ConcurrentHashMap将数组的每个头节点作为锁,如果多个线程访问的头节点不同,则不会冲突。
注:构造参数代表的含义不同,capacity 指的是将要放的元素个数,系统需要根据这个数自行计算初始容量。factor指的是初始化容量时扩容的阈值的负载因子,之后的扩容阈值的负载因子还是0.75。
每个节点在处理完(迁移)之后,会被标记为forwardingNode,其他线程访问的时候,将会直接到达新的map对应的新的节点上。
线程池的核心参数
- corePoolSize,核心线程数目,最多保留的线程数。
- maximumPoolSize,最大线程数目,即:核心线程+救急线程。
- keepAliveTime,生存时间,针对救急线程。
- unit,时间单位,针对救急线程。
- workQueue,任务阻塞队列。
- threadFactory,线程工厂,可以为线程创建时起个好名字。
- handler,拒绝策略,超过最大线程数时的策略,四种:
- ThreadPoolExecutor.AbortPolicy(),抛出异常。
- ThreadPoolExecutor.CallerRunsPolicy(),由调用者去执行该任务,比如调用者是主线程,则由main函数去执行该任务。
- ThreadPoolExecutor.DiscardPolicy(),直接丢弃任务。
- ThreadPoolExecutor.DiscardOldestPolicy(),丢弃任务队列中已经等待最久的任务。
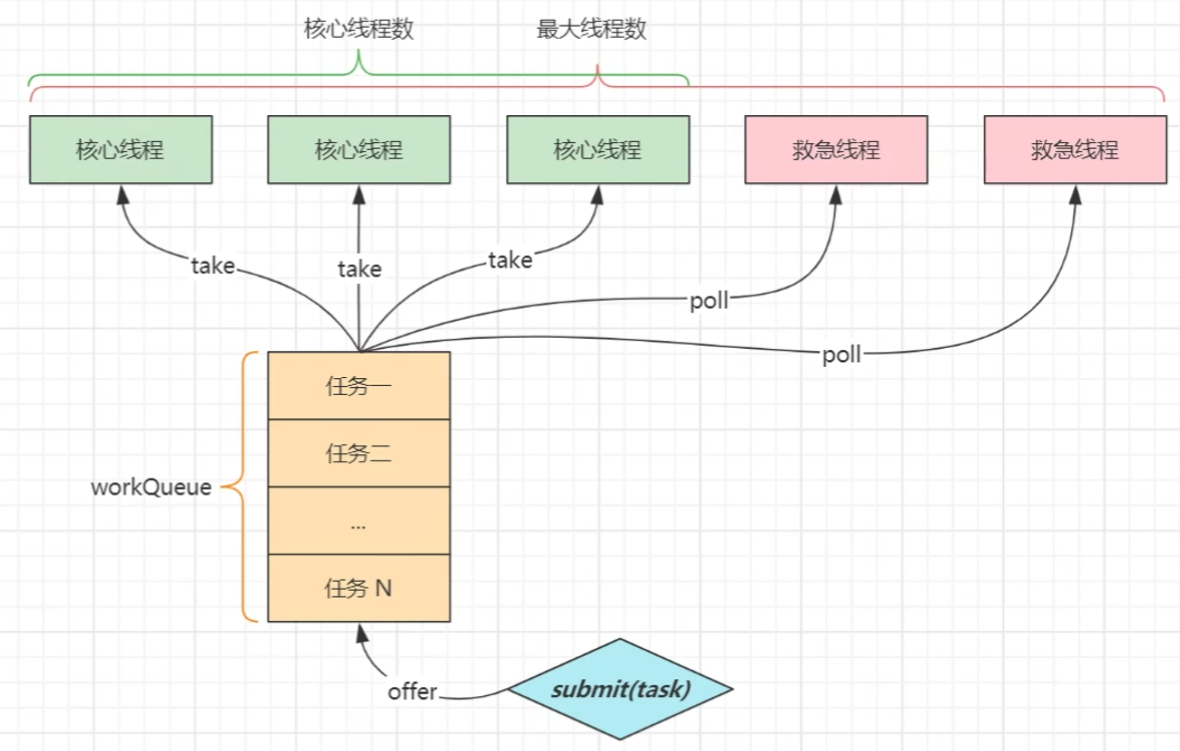
执行流程:
submit()后,如果核心线程以及任务队列都满了,就会创建救急线程。
submit()后,如果超过最大线程数,就触发拒绝策略。
结合业务分析线程池的使用
并发高、任务执⾏时间短的业务怎样使⽤线程池?
并发不⾼、任务执⾏时间⻓的业务怎样使⽤线程池?
并发⾼、 业务执⾏时间⻓的业务怎样使⽤线程池?
⾼并发、任务执⾏时间短的业务:线程池线程数可以设置为CPU核数+1,减少线程上下⽂的切换。
并发不⾼、任务执⾏时间⻓的业务要区分开看:
a)假如是业务时间⻓集中在IO操作上,也就是IO密集型的任务,因为IO操作并不占⽤CPU,所以不要让所有的CPU 闲下来,可以加⼤线程池中的线程数⽬,让CPU处理更多的业务。
b)假如是业务时间⻓集中在计算操作上,也就是计算密集型任务,这个就没办法了,和(a)⼀样吧,线程池中的线 程数设置得少⼀些,减少线程上下⽂的切换。
并发⾼、业务执⾏时间⻓,解决这种类型任务的关键不在于线程池⽽在于整体架构的设计,看看这些业务⾥⾯某些数 据是否能做缓存是第⼀步,增加服务器是第⼆步,⾄于线程池的设置,设置参考(2)。最后,业务执⾏时间⻓的问题, 也可能需要分析⼀下,看看能不能使⽤中间件对任务进⾏拆分和解耦。
如果你提交任务时,线程池队列已满,这时会发⽣什么?
1、如果你使⽤的LinkedBlockingQueue,也就是⽆界队列的话,没关系,继续添加任务到阻塞队列中等待执⾏,因为 LinkedBlockingQueue可以近乎认为是⼀个⽆穷⼤的队列,可以⽆限存放任务;
2、如果你使⽤的是有界队列⽐⽅说ArrayBlockingQueue的话,任务⾸先会被添加到ArrayBlockingQueue中, ArrayBlockingQueue满了,则会使⽤拒绝策略RejectedExecutionHandler处理满了的任务,默认是AbortPolicy。
ThreadLocal作用
ThreadLocal可以实现资源对象的线程隔离,让每个线程各用各的资源对象,避免争用引发的线程安全问题。
ThreadLocal同时实现了线程内的资源共享。
ThreadLocal原理
每个线程内有一个ThreadLocalMap类型的成员变量,用来存储资源对象。
调用set方法时,就是以ThreadLocal自己作为key,资源对象作为value,放入当前线程的ThreadLocalMap中。
调用get方法时,就是以ThreadLocal自己作为key,到当前线程中查找关联的资源值。
调用remove方法时,就是以ThreadLocal自己作为key,移除当前线程关联的资源。
ThreadLocalMap中的key(即ThreadLocal)为什么要设计成弱引用
- Thread可能需要长时间运行(比如线程池中的线程),如果key不再使用,需要在内存不足(GC)时释放其占用的内存。
- GC仅是让key的内存释放,后续还要根据key是否为null来进一步释放值的内存,释放时机有:
- 获取key发现null key。
- set key时,会使用启发式扫描,清除临近的null key,启发次数与元素个数、是否发现null key有关。
- remove时(推荐),因为一般使用ThreadLocal时都把它作为静态变量,因此GC无法回收,需要我们手动调用remove方法进行清理,避免内存泄漏。
⾼并发系统如何做性能优化?如何防⽌库存超卖?
⾼并发系统性能优化: 优化程序,优化服务配置,优化系统配置
- 尽量使⽤缓存,包括⽤户缓存,信息缓存等,多花点内存来做缓存,可以⼤量减少与数据库的交互,提⾼性能。
- ⽤jprofiler等⼯具找出性能瓶颈,减少额外的开销。
- 优化数据库查询语句,减少直接使⽤hibernate等⼯具的直接⽣成语句(仅耗时较⻓的查询做优化)。
- 优化数据库结构,多做索引,提⾼查询效率。
- 统计的功能尽量做缓存,或按每天⼀统计或定时统计相关报表,避免需要时进⾏统计的功能。
- 能使⽤静态⻚⾯的地⽅尽量使⽤,减少容器的解析(尽量将动态内容⽣成静态html来显示)。
- 解决以上问题后,使⽤服务器集群来解决单台的瓶颈问题。
防⽌库存超卖:
悲观锁:在更新库存期间加锁,不允许其它线程修改;
- 数据库锁:select xxx for update;
- 分布式锁;
乐观锁:使⽤带版本号的更新。每个线程都可以并发修改,但在并发时,只有⼀个线程会修改成功,其它会返回失败。
- redis watch:监视键值对,作⽤时如果事务提交exec时发现监视的监视对发⽣变化,事务将被取消。
消息队列:通过 FIFO 队列,使修改库存的操作串⾏化。
总结:总的来说,不能把压⼒放在数据库上,所以使⽤ “select xxx for update” 的⽅式在⾼并发的场景下是不可⾏ 的。FIFO 同步队列的⽅式,可以结合库存限制队列⻓,但是在库存较多的场景下,⼜不太适⽤。所以相对来说,我会倾向于 选择:乐观锁 / 缓存锁 / 分布式锁的⽅式。
JVM
JVM内存结构概述
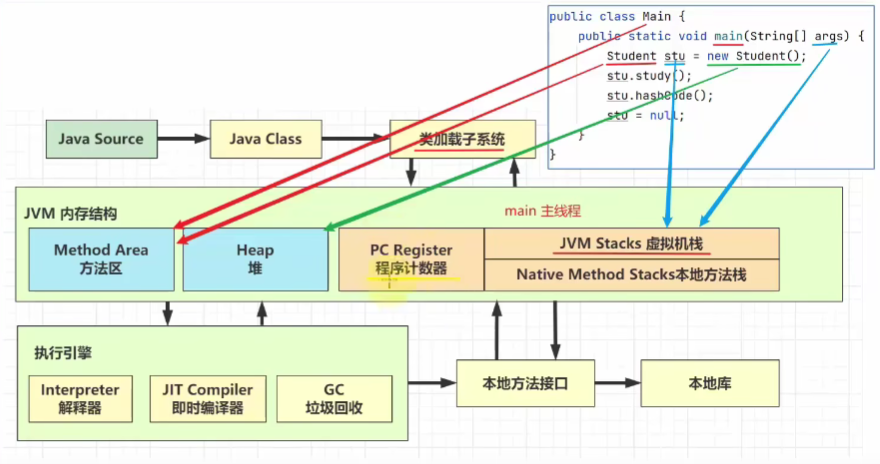
JVM内存结构概述:
方法区:类的信息(包括方法等)。
堆:java实例对象。
栈:局部变量、方法参数、引用。
程序计数器:记录程序执行位置(用于进行类似线程上下文切换的操作)。
本地方法栈是一些系统方法,比如hashCode()。
*解释器:将字节码翻译成平台可执行的机器码,每执行一次代码都需要解释一次。
*即时编译器:缓存热点代码(频繁调用很多次的代码),从而不会一直用解释器。
其中:
- 线程私有:程序计数器、虚拟机栈。
- 线程共享:堆、方法区。
哪些部分会出现内存溢出
除了程序计数器以外,其他地方都有可能产生。
内存溢出类型:
- OutOfMemoryError
- 对内存耗尽,对象越来越多,又一直在使用,不能被垃圾回收。
- 方法区内存耗尽,加载的类越来越多,很多框架都会在运行期间动态产生新的类。
- 虚拟机栈累积,每个线程最多会占用1M内存,线程个数越来越多,而又长时间运行不销毁时。(线程池可以避免该情况)
- StackOverflowError
- 虚拟机栈内部,方法调用次数过多,比如无限递归。
方法区与永久代、元空间的关系
方法区,是JVM规范中定义的一块内存区域,用来存储元数据、方法字节码、即时编译器需要的信息等。
永久代,是Hotspot虚拟机对JVM规范的一种实现(1.8之前)。
元空间,是Hotspot虚拟机对JVM规范的一种实现(1.8之后),使用本地内存作为这些信息的存储空间。
JVM内存参数
对于JVM内存配置参数:-Xmx10240m -Xms10240m -Xmn5120m -XX:SurvivorRatio=3,其最小内存值和Survivor区(from+to两个区)总大小分别是
1 | |
为方便测试,修改虚拟机配置:
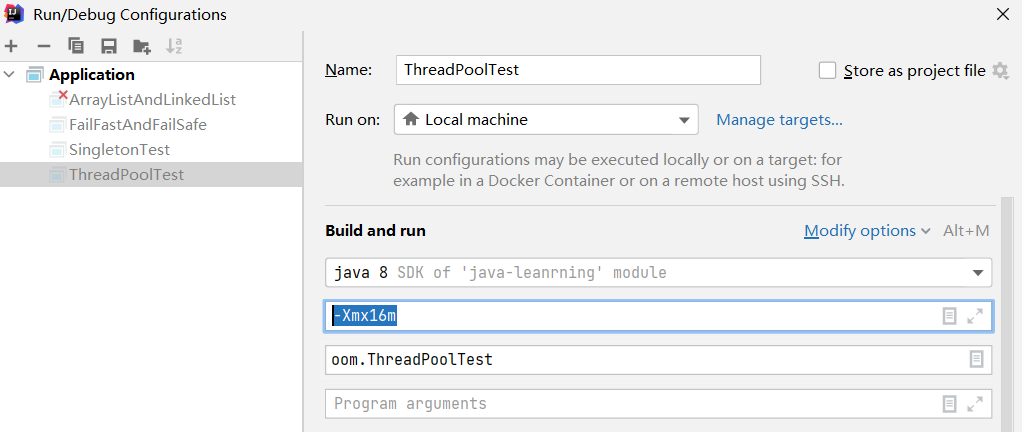
运行后就会发现:
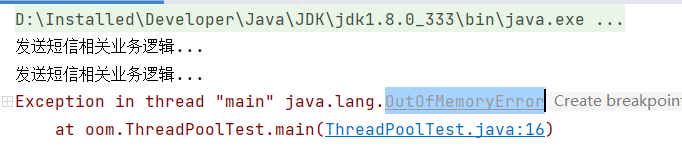
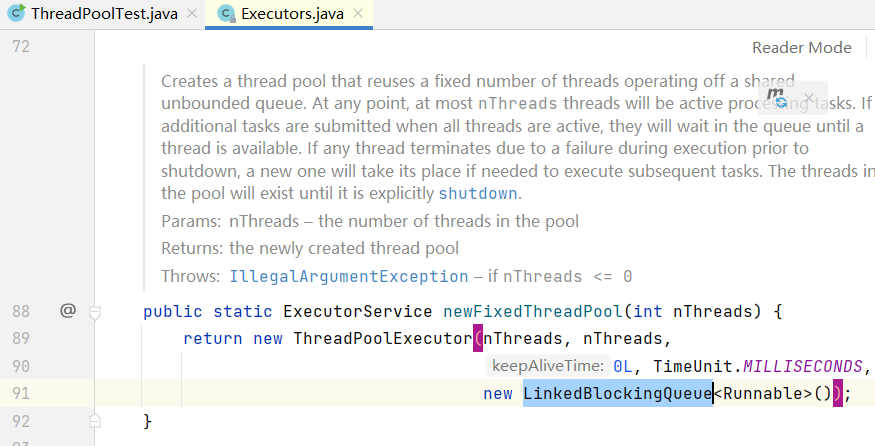
1)误用Executors.newFixedThreadPool(2);,通过查看源码可以知道,它创建的是一个LinkedBlockingQueue,任务队列“无限”的线程池(实际上是capacity = Integer.MAX_VALUE),如果任务队列不断添加任务,占用内存导致内存溢出。
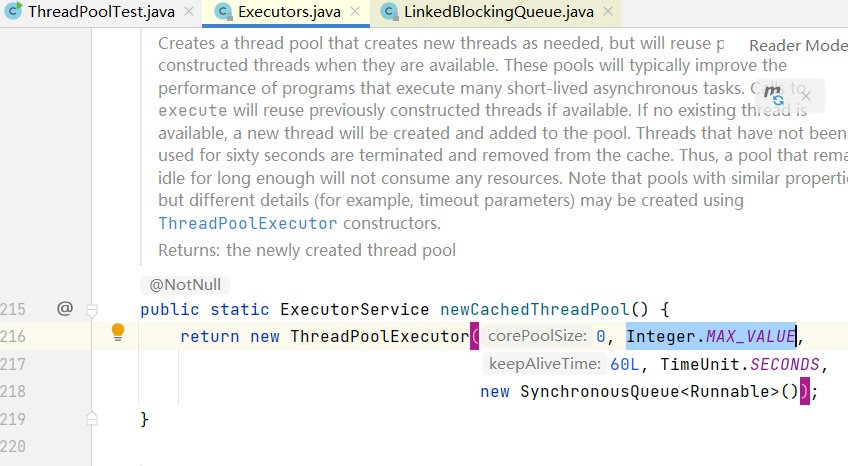
2)误用Executors.newCachedThreadPool();,通过查看其源码可以知道,它创建的是一个有“无限”救助线程的线程池。
查询数据量太大导致的内存溢出
引入jol库:
1 | |
测试代码:
1 | |
本次测试输出 9Mb(10万个这样的Product对象)
所以数据量一旦很大,一个或者多个用户的 findAll()查询 或者 条件失效的查询 将会占用很大的内存,导致内存溢出。
动态生成类导致的内存溢出
比如这样一种情况:
有一个静态的类变量,它内部有个类加载器,可以动态创建类,每次调用它的某个方法就会动态创建类,因为这个类变量是静态的,所以是GC Root,它及其创建的类后在元空间中很难被回收,导致元空间内存溢出。以GroovyShell这个类为例:
测试配置:
1 | |
任意groovy脚本文件一个:
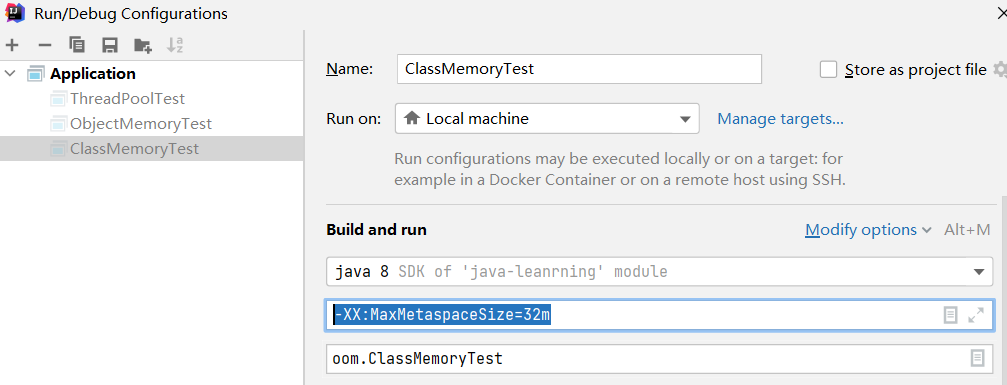
为方便测试,修改JVM运行参数:
测试代码:
1 | |
运行结果:
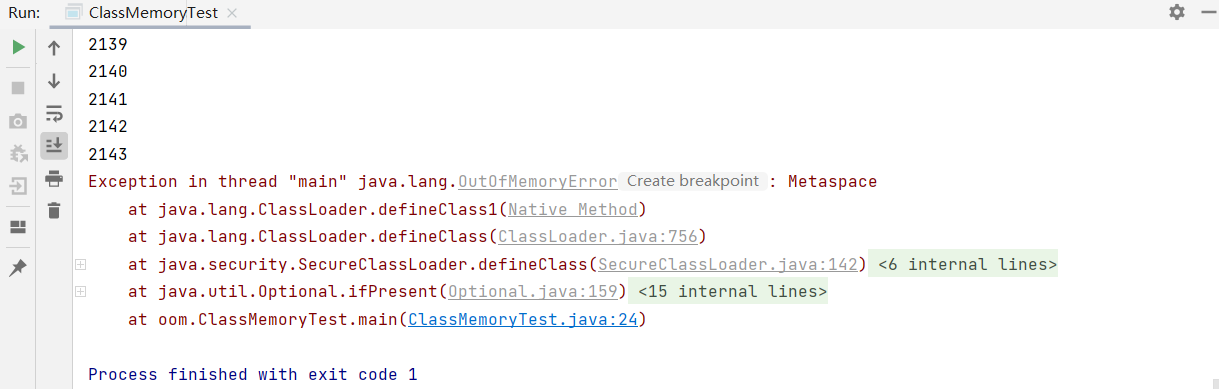
通过运行结果可以看到,在执行了2143次脚本之后,元空间的内存溢出了。
优化方法:将静态变量改为局部变量即可。
1 | |
点击运行,接下来通过jconsole查看内存使用情况:
通过java自带的jconsole工具来查看程序内存的使用情况
注:运行环境一定要跟系统环境变量的版本一致,否则jconsole会一直连接失败。
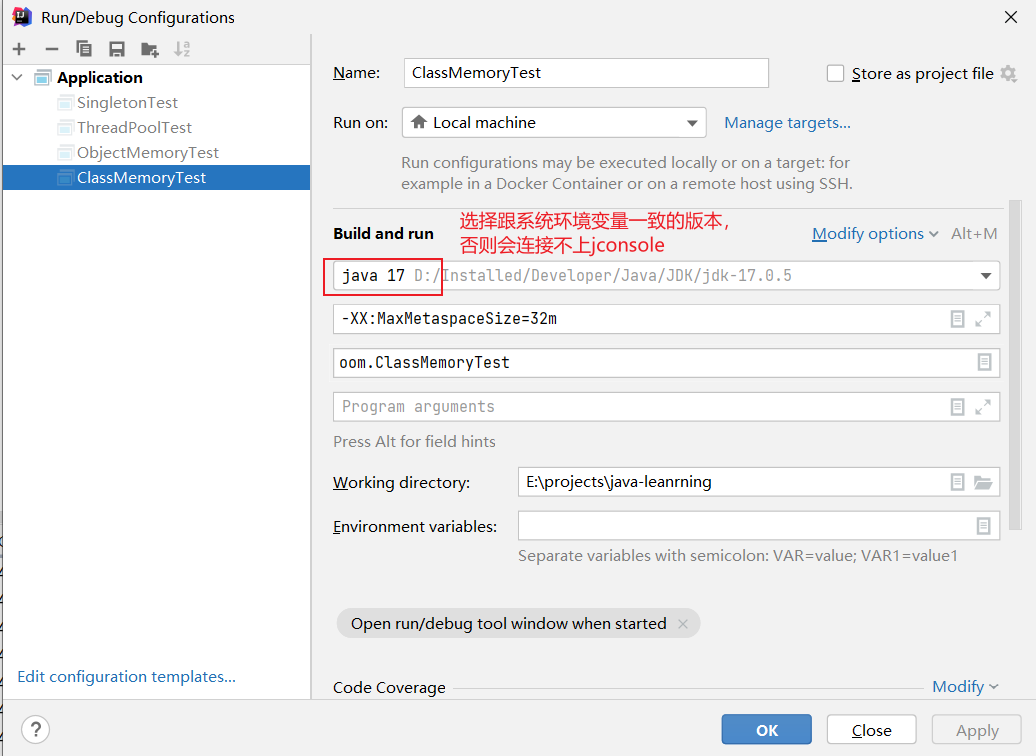
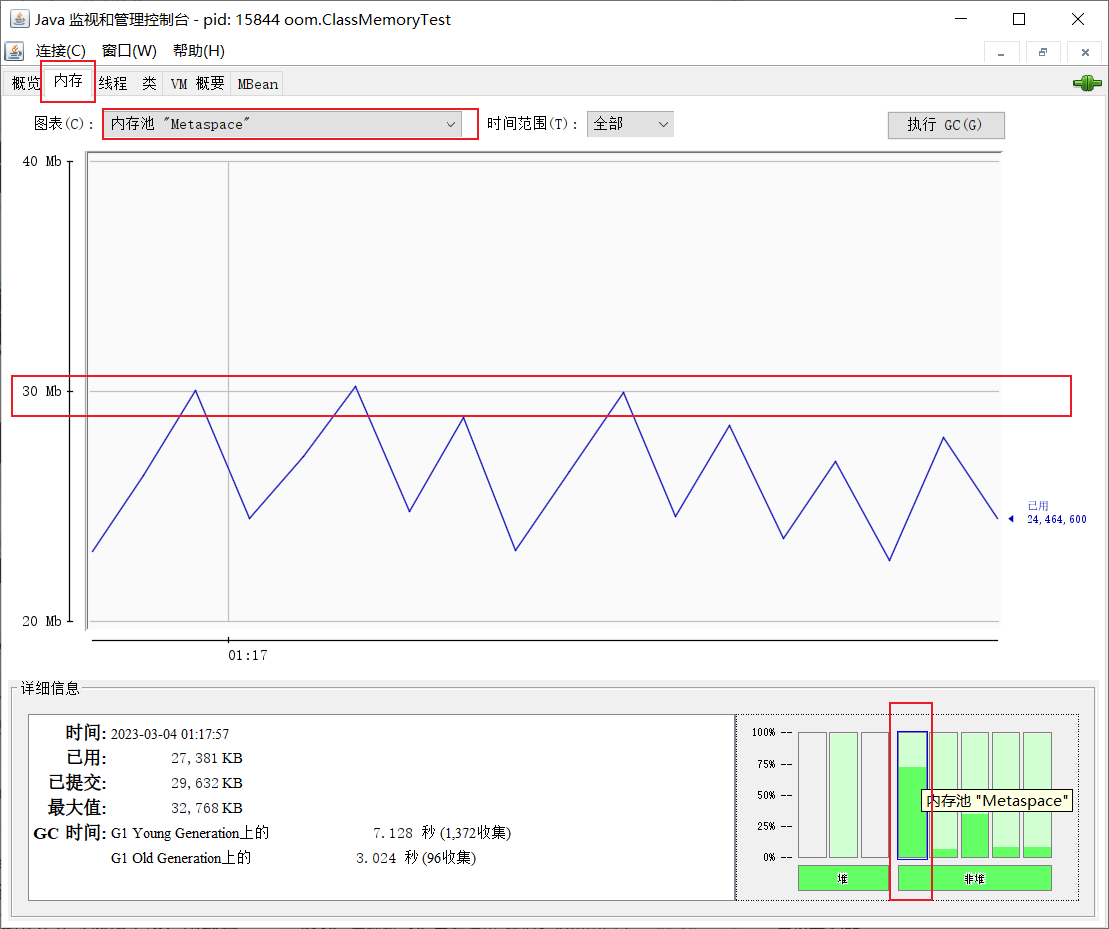
通过jconsole可以看到,元空间的内存现在是不会满了,会自动回收,卸载没有用的类。
类加载
三个阶段:
- 加载
- 将类的字节码载入方法区,并创建类.class对象。
- 如果此类的父类没有加载,先加载父类。
- 加载是懒惰执行。
- 链接
- 验证 - 验证类是否符合class规范,合法性、安全性检查
- 准备 - 为static变量分配空间,设置默认值
- 解析 - 将常量池的符号引用解析为直接引用
- 初始化
- 执行静态代码块与非final的静态变量的赋值
- 初始化是懒惰执行
jhsdb使用
查看方法:结合java自带的jps、jhsdb查看,需要注意的是,在idea中运行程序的jdk版本一定要和jps、jhsdb版本一致,否则会连接失败抛出异常:
1 | |
附:8之后的jdk在安装时会一并安装一个在…/oracle/…目录下,从而导致jdk版本修改不生效问题。
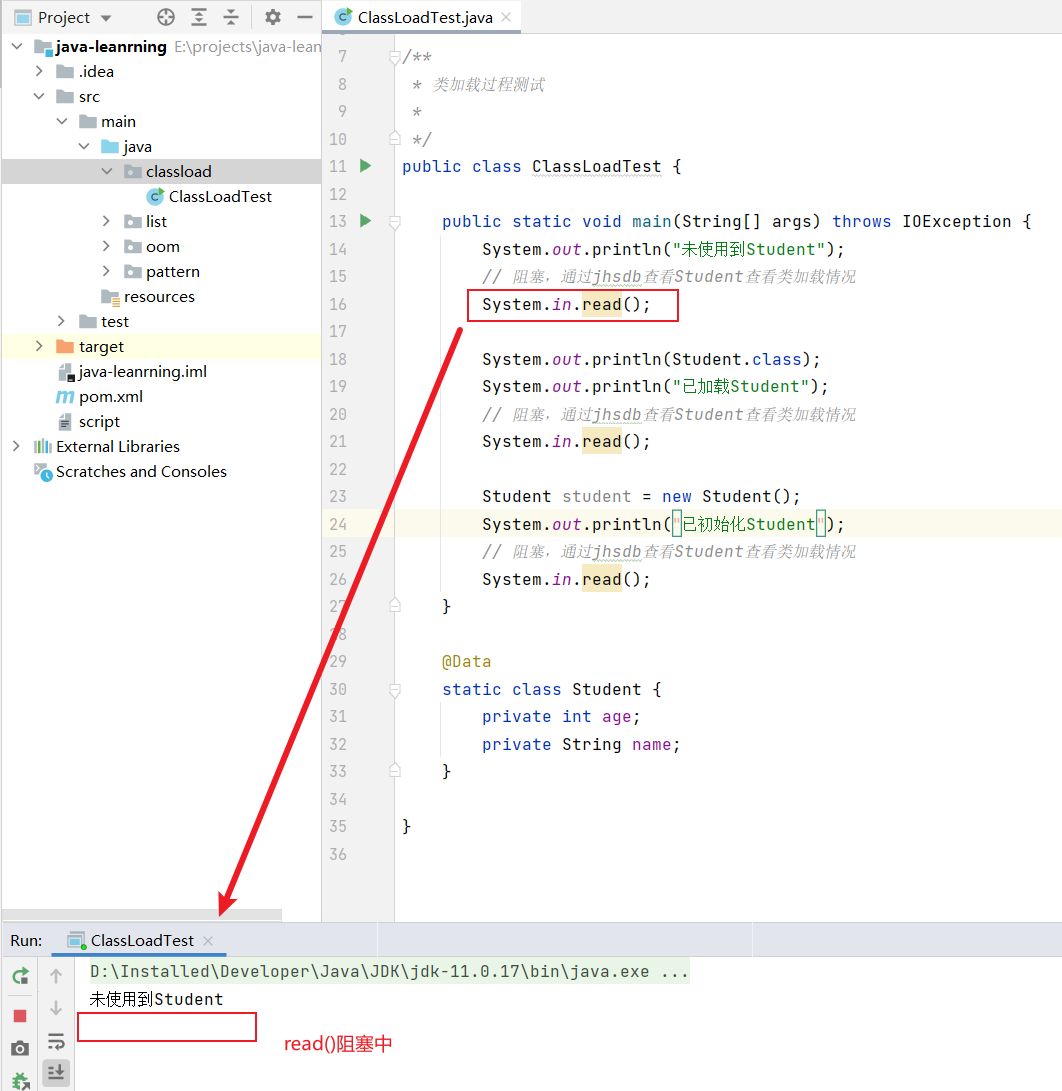
测试代码:
1 | |
运行程序,此时程序在指定位置阻塞:
通过jps查看程序运行的进程号:
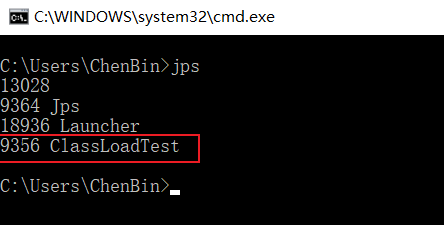
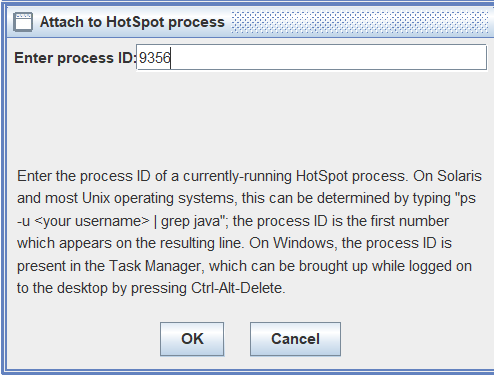
打开jhsdb hsdb命令打开hsdb,并建立连接,输入前面查询到的进程号:
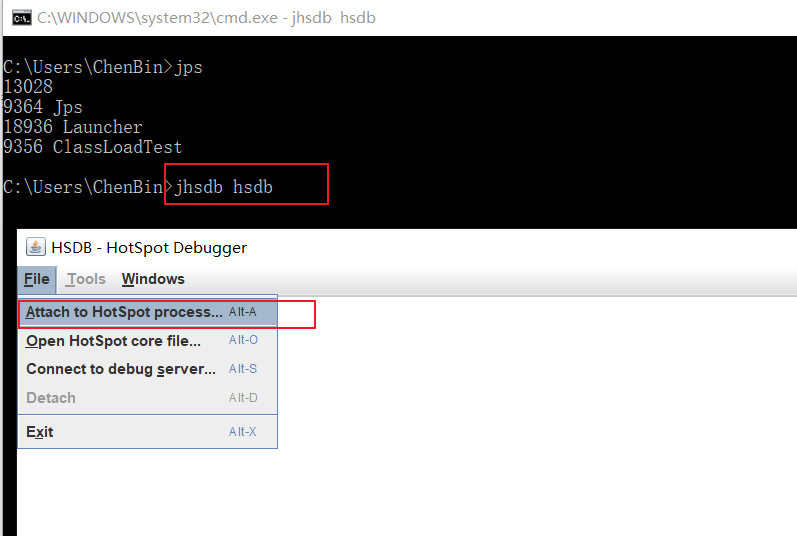
连接成功后,通过 Class Browser 查看类加载情况:
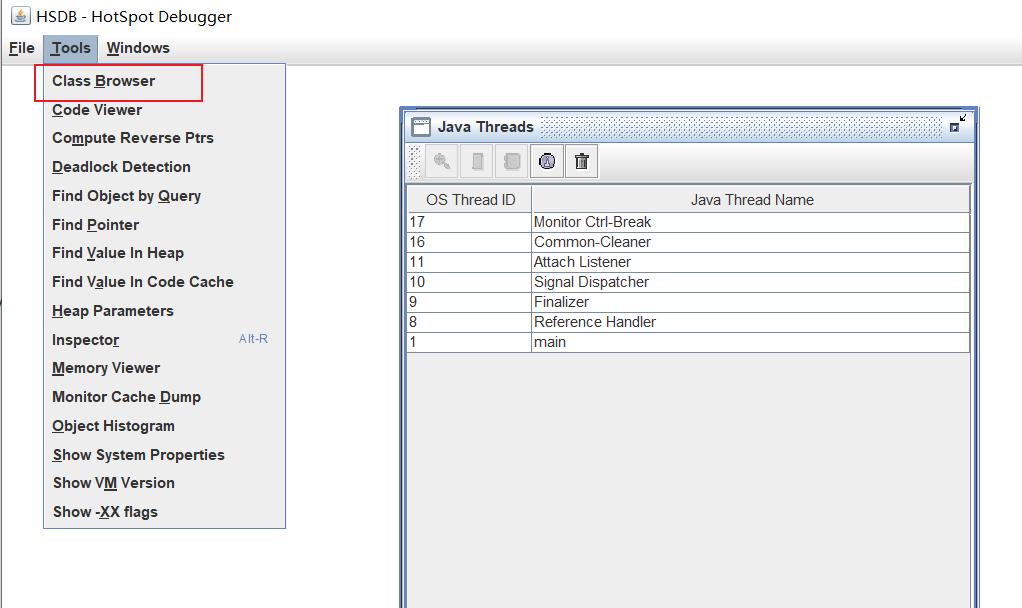
此时无法查看到Student类:
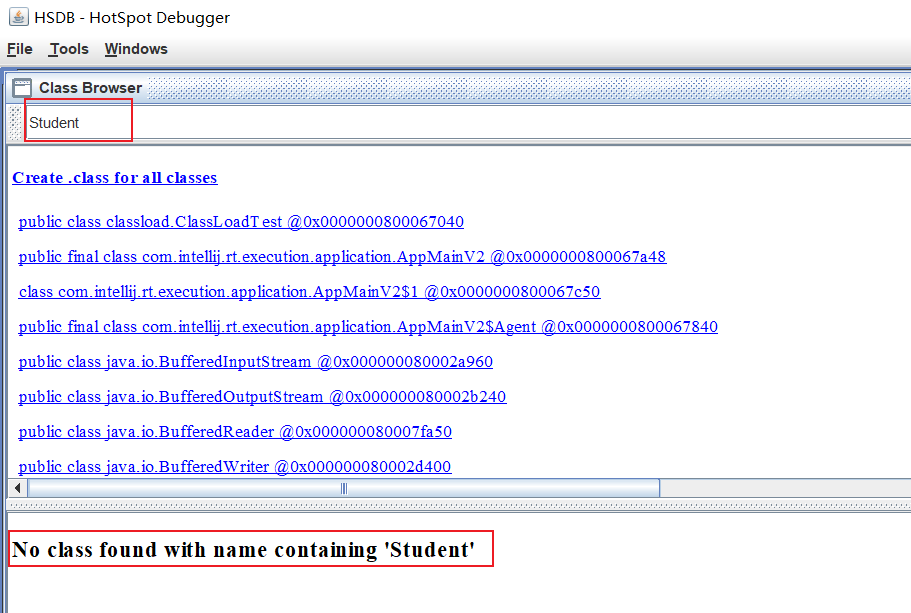
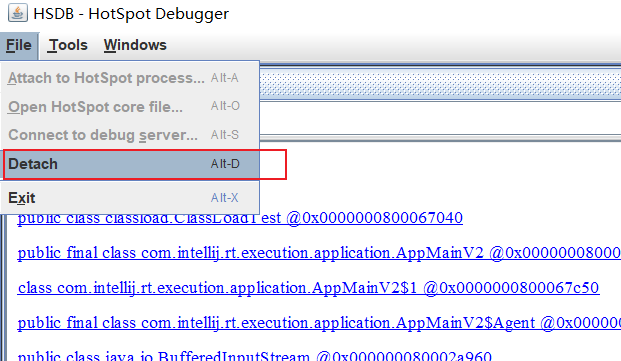
我们先断开连接(必须,否则程序无法继续执行):
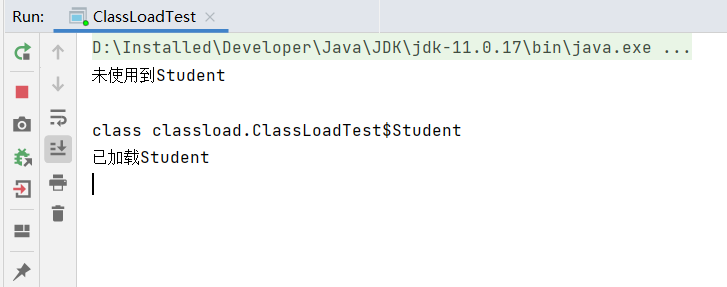
在程序的控制台进行输入操作(回车一下即可),让程序继续执行:
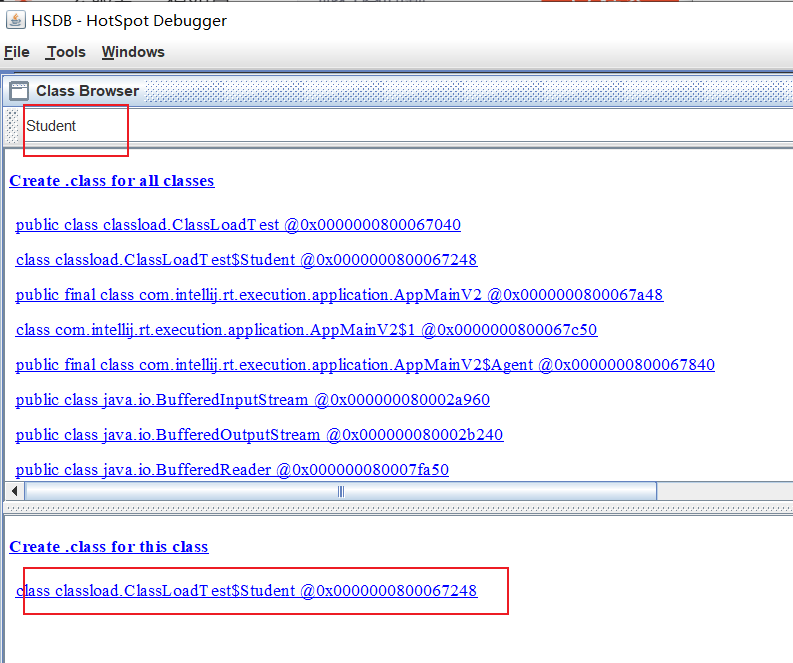
这时我们再连接jhsdb查看类加载情况,发现类已经加载了:
查看jvm内存情况:
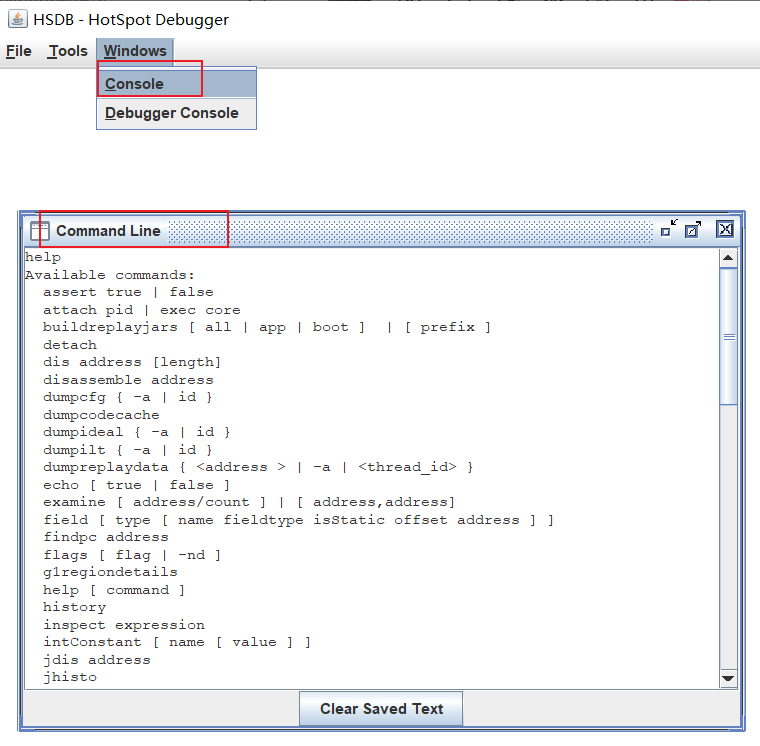
通过help命令可以查看到相关的命令。
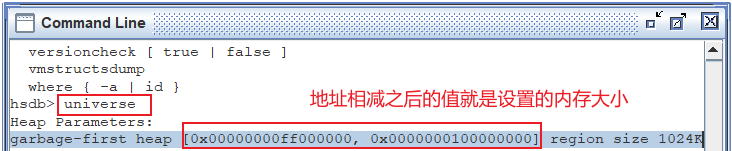
其中,universe命令可以查看内存分布以及大小:
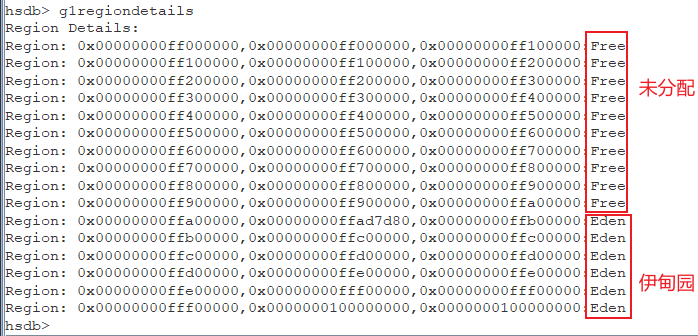
g1regiondetails命令可以查看G1的内存分布情况:
查看字节码文件
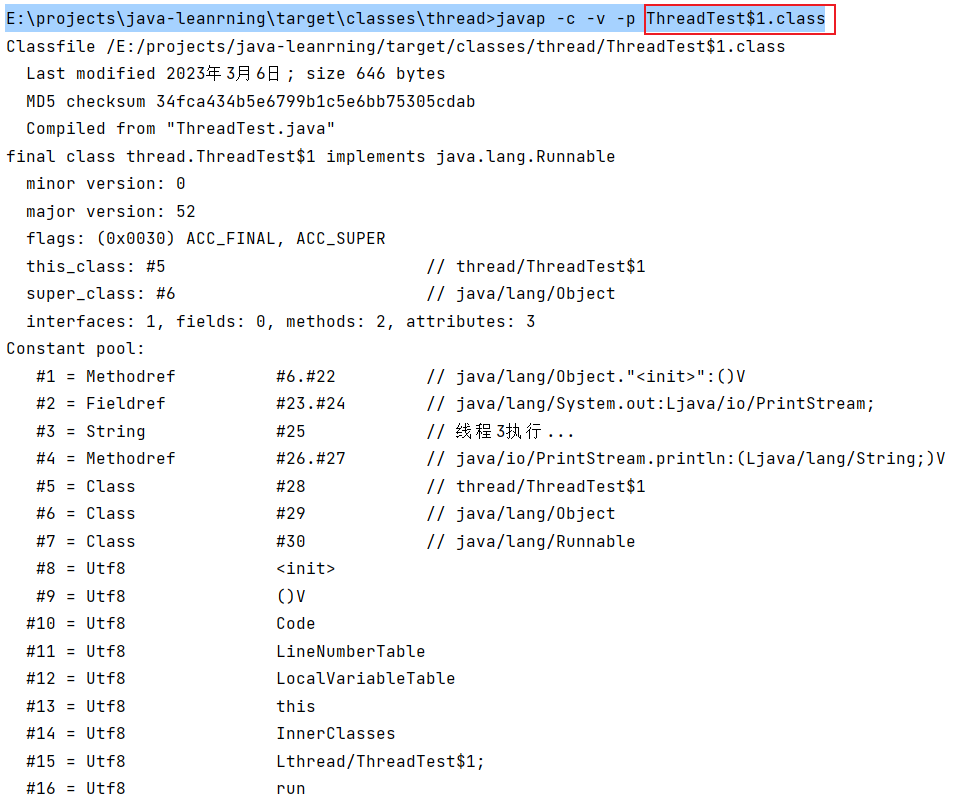
在 /target/class/ 目录的命令行通过 javap -c -v -p XXX.class 可以查看到,如:
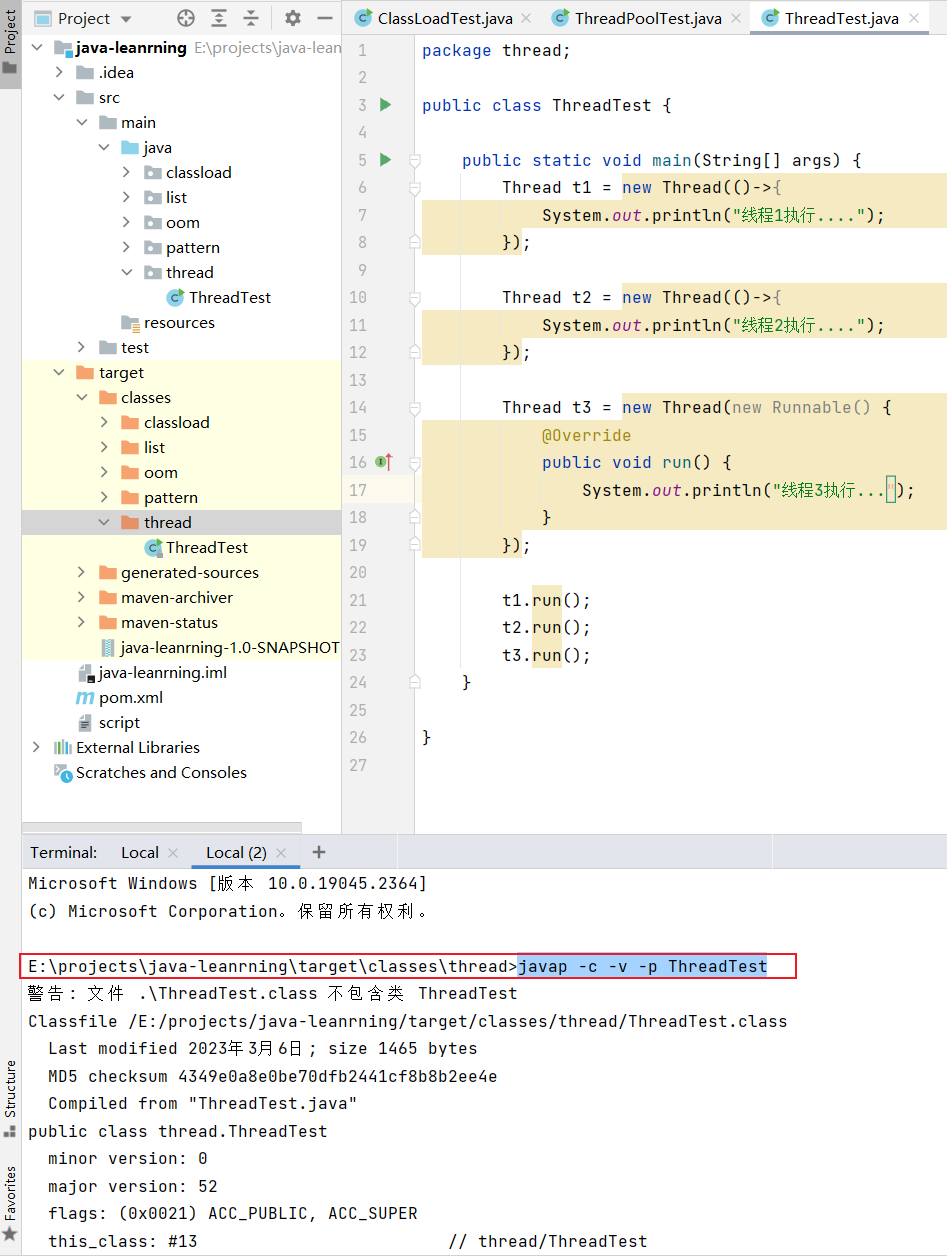
上面的示例中,前两个线程是通过Lambda表达式创建的,线程t3则是通过匿名内部类的方式创建,其区别在于:
扩展:Lambda表达式和匿名内部类的区别
所需类型不同
匿名内部类:可以是接口,也可以是抽象类,还可以是具体类。
Lambda表达式:只能是接口
使用限制不同
如果接口中有且仅有一个抽象方法,可以使用Lambda表达式,也可以使用匿名内部类。
如果接口中多于一个抽象方法,只能使用匿名内部类,而不能使用Lambda表达式。
实现原理不同
匿名内部类:编译之后,产生一个单独的.class字节码文件。
Lambda表达式:编译之后,没有一个单独的.class字节码文件。对应的字节码会在运行的时候动态生成。
双亲委派机制
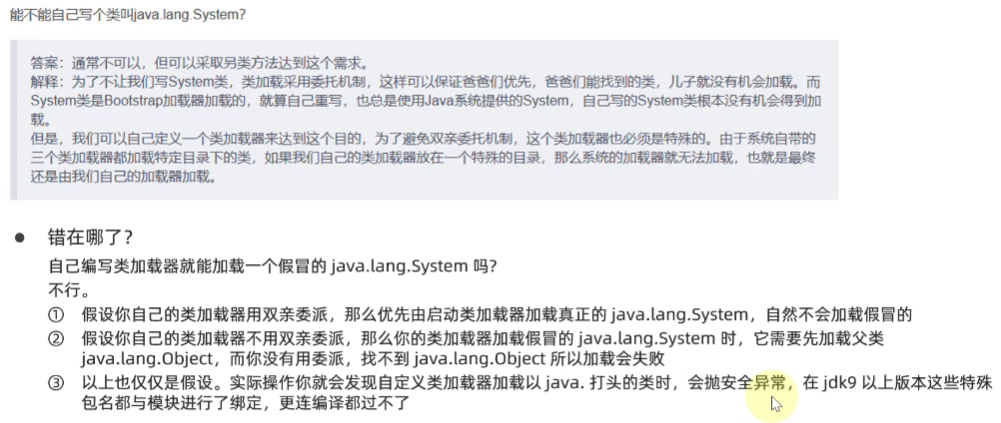
指优先委派上级类加载器进行加载,如果上级类加载器:
- 能找到这个类,由上级加载,加载后该类也对下级加载器可见。
- 不能找到这个类,则下级类加载器才有资格执行加载。

双亲委派的目的:
让上级类加载器中的类对下级共享(反之不行),即能让你的类能依赖到jdk提供的核心类。
让类的加载有优先顺序,保证核心类优先加载。
能不能自己写一个java.lang.System类?
对象的引用类型分为哪几种
强引用
普通变量复制即为强引用,如 A a = new A();
通过GC Root的引用链,如果强引用找不到对象,该对象才能被回收。
软引用
弱引用
虚引用
finalize()相关
它是一个Object中的一个方法,子类重写它,垃圾回收时此方法会被调用,可以在其中进行一些资源释放和清理操作,但是这样操作非常不好,非常影响性能,严重时会引起OOM,所以从JDK9开始就被标记为过时方法了。
存在的问题:
- finalize()方法的调用次序并不能保证。
- finalize()是Finalizer这个守护线程去执行的。
- finalize()中的代码并不能保证被执行。
- 如果finalize()中出现异常,异常不会被输出。
- 垃圾回收时会立刻调用finalize()方法吗?
Spring
解释 Spring 支持的几种 bean 的作用域
Spring 框架支持以下五种 bean 的作用域:
- singleton : bean 在每个 Spring ioc 容器中只有一个实例。
- prototype:一个 bean 的定义可以有多个实例。
- request:每次 http 请求都会创建一个 bean,该作用域仅在基于 web 的 Spring ApplicationContext 情形下有效。
- session:在一个 HTTP Session 中,一个 bean 定义对应一个实例。该作用域 仅在基于 web 的 Spring ApplicationContext 情形下有效。
- global-session:在一个全局的 HTTP Session 中,一个 bean 定义对应一个实 例。该作用域仅在基于 web 的 Spring ApplicationContext 情形下有效。
- 缺省的 Spring bean 的作用域是 Singleton。
Spring 框架中的单例 Beans 是线程安全的么?
Spring 框架并没有对单例 bean 进行任何多线程的封装处理。关于单例 bean 的线程安全和并发问 题需要开发者自行去搞定。但实际上,大部分的 Spring bean 并没有可变的状态(比如 Serview 类 和 DAO 类),所以在某种程度上说 Spring 的单例 bean 是线程安全的。如果你的 bean 有多种状 态的话(比如 View Model 对象),就需要自行保证线程安全。 最浅显的解决办法就是将多态 bean 的作用域由“singleton”变更为“prototype”。