函数使用 把函数作为参数 1 2 3 4 5 import mathdef add_sqrt (x, y, f ):return f(x) + f(y)print add(25 , 9 , math.sqrt)
python内置高级函数 map()函数 1 2 3 4 5 6 7 8 9 10 11 12 13 def format_name (s ):return s[0 ].upper() + s[1 :].lower()print map (format_name, ['adam' , 'LISA' , 'barT' ])def fn (x ):return x*xprint map (fn, [1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 ])
reduce()函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def f (x, y ):return x + yprint reduce(f, [1 , 3 , 5 , 7 , 9 ])1 , 3 , 5 , 7 , 9 ], 100 )
filter()函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def is_odd (x ):return x % 2 == 1 print filter (is_odd, [1 , 4 , 6 , 7 , 9 , 12 , 17 ])def is_not_empty (s ):return s and len (s.strip()) > 0 print filter (is_not_empty, ['test' , None , '' , 'str' , ' ' , 'END' ])import mathdef is_sqr (x ):int (math.sqrt(x))return r*r==xprint filter (is_sqr, range (1 , 101 ))
sorted()函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 sorted ([36 , 5 , 12 , 9 , 21 ])def reversed_cmp (x, y ):if x > y:return -1 if x < y:return 1 return 0 sorted ([36 , 5 , 12 , 9 , 21 ], reversed_cmp)def calc_prod (lst ):def lazy_prod ():def f (x,y ):return x * yreturn reduce(f, lst, 1 )return lazy_prod1 , 2 , 3 , 4 ])print f()
python 中的闭包 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 def count ():for i in range (1 , 4 ):def f ():return i*ireturn fsdef count ():for i in range (1 , 4 ):def f (j ):def g ():return j*jreturn greturn fsprint f1(), f2(), f3()
python 中的匿名函数 lambda 表达式 1 2 3 4 map (lambda x: x * x, [1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 ])
无参数decorator 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 def logCallMethodName (f ):def fn (x ):print 'call ' + f.__name__ + '()...' return f(x)return fn@logCallMethodName def factorial (n ):return reduce(lambda x,y: x*y, range (1 , n+1 ))print factorial(10 )3628800 @logCallMethodName def add (x, y ):return x + yprint add(1 , 2 )def log (f ):def fn (*args, **kw ):print 'call ' + f.__name__ + '()...' return f(*args, **kw)return fnimport timedef performance (f ):def fn (*args, **kw ):print 'call %s() in %fs' %(f.__name__, (endTime - startTime))return rreturn fn@performance def factorial (n ):return reduce(lambda x,y: x*y, range (1 , n+1 ))print factorial(10 )
带参数decorator 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 def log (f ):def fn (x ):print 'call ' + f.__name__ + '()...' return f(x)return fn@log('DEBUG' def my_func ():'DEBUG' )'DEBUG' )@log_decorator def my_func ():def log (prefix ):def log_decorator (f ):def wrapper (*args, **kw ):print '[%s] %s()...' % (prefix, f.__name__)return f(*args, **kw)return wrapperreturn log_decorator@log('DEBUG' def test ():pass print test()def log_decorator (f ):def wrapper (*args, **kw ):print '[%s] %s()...' % (prefix, f.__name__)return f(*args, **kw)return wrapperreturn log_decoratordef log (prefix ):return log_decorator(f)import timedef performance (unit ):def perf_decorator (f ):def wrapper (*args, **kw ):1000 if unit == 'ms' else endTime - startTimeprint 'call %s() in %f %s' % (f.__name__, costTime, unit)return rreturn wrapperreturn perf_decorator@performance('ms' def factorial (n ):return reduce(lambda x,y: x*y, range (1 , n+1 ))print factorial(10 )print factorial.__name__import time, functoolsdef performance (unit ):def perf_decorator (f ): @functools.wraps(f ) def wrapper (*args, **kw ):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 print int ('12345' )print int ('12345' , base=8 )print int ('12345' , 16 )def int2 (x, base=2 ):return int (x, base)print int2('1000000' )import functoolsint , base=2 )'1000000' )
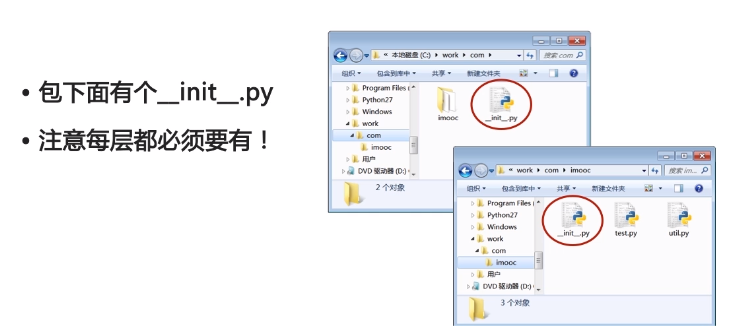
模块 区分包和普通目录 包下面一定要有一个__init__.py文件(且每一层都要有),哪怕是一个空文件。
导入模块 要使用一个模块,我们必须首先导入该模块。Python使用import语句导入一个模块。例如,导入系统自带的模块 math:
如果我们只希望导入用到的math模块的某几个函数,而不是所有函数,可以用下面的语句:
1 from math import pow , sin, log
如果遇到名字冲突怎么办?比如math模块有一个log函数,logging模块也有一个log函数,如果同时使用,如何解决名字冲突?
如果使用import导入模块名,由于必须通过模块名引用函数名,因此不存在冲突:
1 2 3 import math, loggingprint math.log(10 ) 10 , 'something' )
如果使用 from…import 导入 log 函数,势必引起冲突。这时,可以给函数起个“别名”来避免冲突:
1 2 3 4 from math import logfrom logging import log as logger print log(10 ) 10 , 'import from logging' )
所以导入模块的方式可总结如下四种(以导入Python的os.path模块为例,该模块提供了 isdir() 和 isfile()函数,判断指定的目录和文件是否存在):
1 2 3 4 import osimport os.pathfrom os import pathfrom os.path import isdir, isfile
python中动态导入模块(导入模块时出现异常的处理)
如果导入的模块不存在,Python解释器会报 ImportError 错误:
1 2 3 Traceback (most recent call last):"<stdin>" , line 1 , in <module>
例如:Python 2.6/2.7提供了json 模块,但Python 2.5以及更早版本没有json模块,不过可以安装一个simplejson模块,这两个模块提供的函数签名和功能都一模一样。
所以导入方式可以以如下的方式:
1 2 3 4 try :import jsonexcept ImportError:import simplejson as json
安装第三方模块 1 2 3 4 # 方式1 # 方式2(推荐,已内置到2.7+)
第三方模块可以从以下地址获取到:
https://pypi.org/
类与实例 定义类并创建实例 1 2 class Person (object ):pass
按照 Python 的编程习惯,类名以大写字母开头,紧接着是(object),表示该类是从哪个类继承下来的。
1 2 3 4 5 6 7 class Person (object ):pass print xiaomingprint xiaohongprint xiaoming == xiaohong
实例赋值:(两个 Person 类的实例的 list,并给两个实例的 name 赋值,然后按照 name 进行排序。)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Person (object ):pass 'Bart' 'Adam' 'Lisa' sorted (L1, lambda p1, p2: cmp(p1.name, p2.name))print L2[0 ].nameprint L2[1 ].nameprint L2[2 ].name
初始化实例属性(类似与Java的构造函数) 在定义 Person 类时,可以为Person类添加一个特殊的__init__()方法,当创建实例时,init ()方法被自动调用,我们就能在此为每个实例都统一加上以下属性:
1 2 3 4 5 class Person (object ):def __init__ (self, name, gender, birth ):
注意:init () 方法的第一个参数必须是 self(也可以用别的名字,但建议使用习惯用法),后续参数则可以自由指定,和定义函数没有任何区别。相应地,创建实例时,就必须要提供除 self 以外的参数:
1 2 xiaoming = Person('Xiao Ming' , 'Male' , '1991-1-1' )'Xiao Hong' , 'Female' , '1992-2-2' )
访问属性使用 . 操作符:
1 2 3 4 print xiaoming.nameprint xiaohong.birth
定义Person类的__init__方法,除了接受 name、gender 和 birth 外,还可接受任意关键字参数,并把他们都作为属性赋值给实例:
(还可以通过 setattr(self, ‘name’, ‘xxx’) 设置属性。)
1 2 3 4 5 6 7 8 9 10 class Person (object ):def __init__ (self, name, gender, birth, **kw ):for k, v in kw.iteritems():setattr (self, k, v)'Xiao Ming' , 'Male' , '1990-1-1' , job='Student' )print xiaoming.nameprint xiaoming.job
对象属性访问控制 Python对属性权限的控制是通过属性名来实现的,如果一个属性由双下划线开头(__),该属性就无法被外部访问。
1 2 3 4 5 6 7 8 9 class Person (object ):def __init__ (self, name, score ):'Bob' , 59 )print p.nameprint p.__score
python中创建类属性(类似于Java中的静态变量) 类本身也是一个对象,如果在类上绑定一个属性,则所有实例都可以访问类的属性,并且,所有实例访问的类属性都是同一个!也就是说,实例属性每个实例各自拥有,互相独立,而类属性有且只有一份。
定义类属性可以直接在 class 中定义:
1 2 3 4 class Person (object ):'Earth' def __init__ (self, name ):
获取类属性:
对一个实例调用类的属性也是可以访问的,所有实例都可以访问到它所属的类的属性:
1 2 3 4 5 6 p1 = Person('Bob' )'Alice' )print p1.addressprint p2.address
1 2 3 4 5 Person.address = 'China' print p1.addressprint p2.address
python中类属性和实例属性名字冲突 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Person (object ):'Earth' def __init__ (self, name ):'Bob' )'Alice' )print 'Person.address = ' + Person.address'China' print 'p1.address = ' + p1.addressprint 'Person.address = ' + Person.addressprint 'p2.address = ' + p2.address
结果如下:
1 2 3 4 Person.address = Earth
我们发现,在设置了 p1.address = ‘China’ 后,p1访问 address 确实变成了 ‘China’,但是,Person.address和p2.address仍然是’Earch’,怎么回事?
原因是 p1.address = ‘China’并没有改变 Person 的 address,而是给 p1这个实例绑定了实例属性address ,对p1来说,它有一个实例属性address(值是’China’),而它所属的类Person也有一个类属性address,所以:
访问 p1.address 时,优先查找实例属性,返回’China’。
访问 p2.address 时,p2没有实例属性address,但是有类属性address,因此返回’Earth’。
可见,当实例属性和类属性重名时,实例属性优先级高,它将屏蔽掉对类属性的访问。
当我们把 p1 的 address 实例属性删除后,访问 p1.address 就又返回类属性的值 ‘Earth’了:
1 2 3 del p1.addressprint p1.address
可见,千万不要在实例上修改类属性,它实际上并没有修改类属性,而是给实例绑定了一个实例属性。
python中定义实例方法(类似Java中的 getter/setter 方法) 一个实例的私有属性就是以__开头的属性,无法被外部访问,那这些属性定义有什么用?
虽然私有属性无法从外部访问,但是,从类的内部是可以访问的。除了可以定义实例的属性外,还可以定义实例的方法。
实例的方法就是在类中定义的函数,它的第一个参数永远是 self,指向调用该方法的实例本身,其他参数和一个普通函数是完全一样的:
1 2 3 4 5 6 7 8 9 class Person (object ):def __init__ (self, name ):def get_name (self ):return self.__name'Bob' )print p1.get_name()
例2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Person (object ):def __init__ (self, name, score ):def get_grade (self ):if self.__score >= 80 :return 'A' if self.__score >= 60 :return 'B' return 'C' 'Bob' , 90 )'Alice' , 65 )'Tim' , 48 )print p1.get_grade()print p2.get_grade()print p3.get_grade()
python中定义类方法(类似Java中的静态方法) 通过标记一个 @classmethod,该方法将绑定到 Person 类上,而非类的实例。类方法的第一个参数将传入类本身,通常将参数名命名为 cls
1 2 3 4 5 6 7 8 9 10 11 12 13 class Person (object ):0 @classmethod def how_many (cls ):return cls.__countdef __init__ (self, name ):1 print Person.how_many()'Bob' )print Person.how_many()